Sequel Migrations on Heroku
2011-11-30 10:39:02 by jdixon
I find myself using Sequel in conjunction with Sinatra these days to write more of my web applications. Never having been a fan of ORMs in general, and mostly comfortable with the ickier bits of SQL wizardry, it took me a while to warm up to the idea of using one for database migrations. But I've seen the possibilities with stuff like ActiveRecord. Being able to migrate my schema into a versioned state is "dee-lish".
- Comments (0)
Wherefore art thou, BankSimple?
2011-10-01 16:46:33 by jdixon
Ever since I first heard about BankSimple over a year ago, I've been anxiously awaiting their public launch. They promised to "reinvent personal banking"; to make online banking simpler and effectively, to not suck.
A little over a week ago, the BankSimple blog announced their first look at their online interface. A video walks through their search capabilities and demonstrates how finding data will be much simpler than the traditional online banking UI. Much of what I saw reminded me of Mint.com.
Over the last week I've talked with a number of friends and peers about the BankSimple announcement. Meanwhile we've had events like the OccupyWallStreet protests and backlash to Bank of America's announcement that they'll begin charging customers $60/year for the privilege of using a debit card.
I hope that BankSimple realizes that this is their opportunity in waiting. We don't need another Mint.com (yet). We don't need the Facebook equivalent of online banking. We need a fair, trustworthy banking service that doesn't rape us with fees, avoids predatory behavior and bait-and-switch offerings and isn't constantly focused on their next acquisition. Convenient features, such as depositing checks with a smartphone camera, are great but not a necessity. In short, we need the online equivalent of a good credit union.
Traditional banks have chosen to innovate only where it suits them. I hope that BankSimple can seize this opportunity and usher in a new age of consumer banking. Guys, please don't drop the ball. In the meantime, I think I'll start looking at the alternatives.
- Comments (0)
Thoughts on Surge 2011
2011-09-30 22:03:47 by jdixon
I had another great year at the Surge scalability conference in Baltimore, MD. Many of you know that I consider Surge to be "my baby", having conceived of the original conference vision, name and motto while employed at OmniTI. Even though I've moved on, I'm proud to see it grow and flourish while keeping its intimate feel intact.
Long story short, Surge 2011 kicked ass and took names. The speaker lineup was impressive and there were improvements across the board. Audio and video were outsourced to a professional team. On Thursday, lunch was provided and after the last session, Google had a nice party with plenty of hors d'oevers and beer. Everyone appeared to have a great time, sharing war stories and networking with peers.
I was invited by this year's team to organize the Lightning Talks on Wednesday night. Although I wish I'd scrapped the Karaoke PowerPoint event as I was inclined to do, the rest of the night went off without a hitch. The talks were consistently awesome, with Adam Jacob putting the capper on the evening.
Sessions on Thursday were excellent. Ben Fried held keynote honors, describing one of his greatest failures and how it helped shape the way Google IT operates. Artur Bergman was typically irreverent towards Linux kernel developers and inferior hardware. My favorite talk of the conference happened to come from Mark Imbriaco, the Director of Cloud Operations at Heroku (and coincidentally, my boss). But seriously, it was a brilliant interactive session full of insightful real-life incident response tactics and Q&A with the audience. Ironically, our Heroku operations team had to skip the 2:30pm slot to respond to an urgent incident within our architecture. My day wrapped up with a hilarious Choose-Your-Own-Adventure talk by Adam Jacob of Opscode.
Friday's sessions were good but struggled to compete with the consistently high quality of the previous day. I enjoyed Theo Schlossnagle's dissection of the Circonus real-time data subsystems, even though I'm intimately familiar with them already (as former Product Manager of the same). I caught the latter portions of Baron Schwartz's talk on performance metrics and the first half of Mike Panchenko's talk on cloud infrastructure. Unfortunately I had to skip the latter half of the conference's last day due to family commitments, but I've heard great things on Twitter about the remaining sessions.
My only real complaint was the Internet connectivity. Unlike last year, where I insisted on using Port Networks exclusively, this year the organizers chose to outsource part of the conference network to the Tremont IT staff. I'm unsure of the specific cause of the failures, but the symptoms were random failures to load TCP connections from various sites. On the first day, for example, I was unable to load the Surge website without it blocking on the Fontdeck CDN. The next day, I couldn't SSH to any EC2 hosts (although I was able to get to my personal server at ARP Networks) or load Basho and Etsy websites. Everyone I spoke with encountered similar failures, but not always the same sites (ruling out DNS issues). It appeared to be caused by overzealous application filtering or possibly a connection limit. I spoke to multiple OmniTI employees and nobody knew what the cause was, other than it had something to do with the Tremont service.
Also, I noticed a distinct lack of war stories as compared to last year's event. Surge was envisioned as a place where internet practitioners could share and learn from each other's mistakes. With a couple distinct exceptions, it just wasn't the case this year. It felt more like a chapter from O'Reilly Strata 2011 (read: Big Data) than Surge 2010. Nevertheless, there was plenty of good information to be gleaned throughout.
I had an incredible time at this year's event with my old friends at OmniTI, my operations and engineering compadres at Heroku, and countless friends and associates from IRC, Twitter and real life. As much as I enjoy conferences like Velocity, OSCON and DevOpsDays, I don't think they hold a candle to the concentration of operational and engineering excellence that you find at Surge. I'm thrilled that they're committed to keeping Surge at the Tremont. Although it's a quirky building with limited modernities, it guarantees that this event will never grow too large or become "commercially compromised". Hope to see all of you (well, 350 of you anyways) again next year.
- Comments (0)
Mad as Hell
2011-09-25 00:24:02 by jdixon
Laid a smackdown of truth on a loudmouth conservative parent at a kid's birthday party today. This guy (another kid's father) complained about pro athletes being "greedy" and how firemen are underpaid and not getting salary increases. I forced myself to get up and explain to him how:
- Both are a result of the supply and demand of the capitalist society he believes so strongly in.
- He's a hypocrite for supporting his own union but decrying the work of the NFL Player's Union.
- While I respect his work and applaud him for his efforts, he chose his profession. Nobody forced him into it. If he wasn't there to do it, someone else would fill the vacuum and happily take his paycheck.
- Blaming Obama, or Bush, or even Clinton for his woes is asinine. The toxic state of our government is a direct result of unbridled capitalism that's run unchecked for the last 30 years and continues to deteriorate.
- Corporations like GE earn $14B in profits but pay zero in taxes.
- Iraq didn't attack the United States, Al Qaeda did. We invaded Iraq without cause and continue to participate in wars without justification.
- The aforementioned reasons are why our government programs and agencies are struggling to make ends meet, not because of "entitlements" paid out to citizens who've earned their social security.
- We can't continue to support an upper-class that refuses to pay forward their dues to society.
Generally speaking, I'm a timid sort at social affairs. I'll keep to myself with a soda and my phone. But I heard this guy ranting and called him out on it. I shouldn't brag, but I'm fucking proud of standing up for my beliefs today. And to his credit, this guy had the decency to listen to what I was saying and, as best as I could tell, actually made sense of what he heard. At the end we shook hands and agreed that it's good to talk about these issues in healthy debate in public.
I don't know what came over me. It might have something to do with me watching Network again this week. Although the film is 35 years old, it's a striking narrative of today's problems in politics, mainstream media and corporate America. I'm tired of the ignorant posturing by both sides, fueled by self-serving tabloid hawkers and a political system tainted by corporate greed. There are decent people on both sides of the two-party spectrum but we're forced to eat from the news feedbag with a hood over our eyes.
I think Howard Beale said it best.
- Comments (1)
Why the Netflix Pivot Will Fail
2011-09-19 12:12:27 by jdixon
Netflix has always been about convenience. They killed Blockbuster on customer service, convenience and price. They've continued to compete against up-and-comers like Redbox thanks to their streaming offering. Netflix CEO Reed Hastings feels that now is the time for an epic pivot, allowing each product to stand (and compete) on its own.
As a cohesive unit with simplified billing, and offering customers the flexibility and choice they're accustomed to, Netflix is ubiquitous. Thanks to a loyal and addicted user base, they've made inroads with a multitude of video and gaming appliances. Consumers pushed for Netflix access on their TiVos and Xboxen, and TV manufacturers are starting to include Netflix support in newer "smart TVs".
And yet, I predict that Netflix/Qwikster will be dead within three years. The move to independent business units a) results in higher prices, b) makes it less convenient for viewers, and c) removes operational and marketing efficiencies found in their current business operations.
Redbox will continue to chip away at the Qwikster "legacy" DVD market. Who wants to wait 2 days for a DVD when I can pick one up in 10 minutes from the corner Walgreens? And how long before the movie studios push Netflix aside for more lucrative, direct partnerships with the appliance manufacturers and vendors?
Hastings is trying to sell the vision that this is a necessary pivot to remain viable in the market. Rather, I suspect this is their attempt to increase short-term shareholder value. I chose to stick with Netflix through the recent price hikes for the continued convenience of one-stop shopping. But with the lack of streaming choice, separate bills, and less convenient DVD rentals, I don't see myself sticking around for long.
- Comments (0)
Why Chef pwns Puppet
2011-09-10 09:18:16 by jdixon

I don't know why, it just does. Seriously, Ruby just destroys Puppet's DSL. I guess that's not really a vote for Chef as much as it is an incrimination of poor DSLs. Either way I'm 10x as productive with a fraction of the hair loss.
Thanks, Opscode.
- Comments (1)
PostgreSQL 9.0 createdb Revelations (Updated)
2011-08-27 15:18:16 by jdixon
One of my first projects at Heroku has been to modernize our shared PostgreSQL offering (working with @asenchi). As we get closer to internal testing of our new service, @markimbriaco asked for benchmarks looking for any bottlenecks in PostgreSQL 9.x when creating large quantities of small databases. We've seen instances where Pg 8.3 will start to choke after 2000 databases on the same server and we're hoping that 9.x alleviates this issue.
My initial test was overly simplistic but still revealed some interesting patterns. I started with createdb on the command-line, generating 8000 roles and empty databases, serially. The results were promising, with PostgreSQL 9.0.4 (Ubuntu 10.04) able to scale up without any noticeably increasing latency. Unfortunately, it's not a terribly useful benchmark given the absence of any workload. And yet, I couldn't help but notice a pattern in the scatter plot:
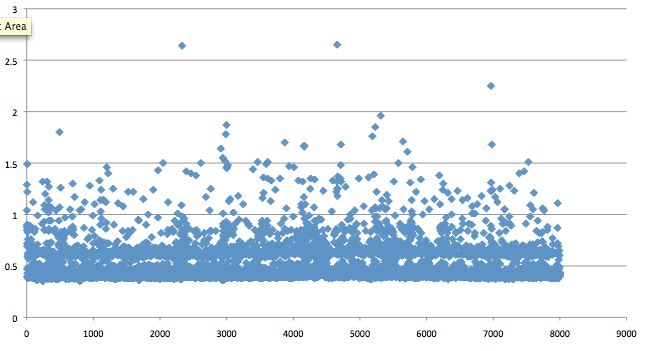
Notice the gap between 500 and 600 ms? I don't have an explanation for this but I suspected that Pg has an internal condition that triggers for actions that take 500ms or longer. Regardless, our primary expectations had been met. Whatever bottleneck 8.3 demonstrated when creating databases on a server with large quantities of existing small databases appears to be fixed in 9.0.
The next test was to run a similar sequence with our new application server. It offers an internal RESTful API using Sinatra and Sequel to provision and manage customer databases on shared servers. The results for this run were even more enlightening. Check out the stratification:
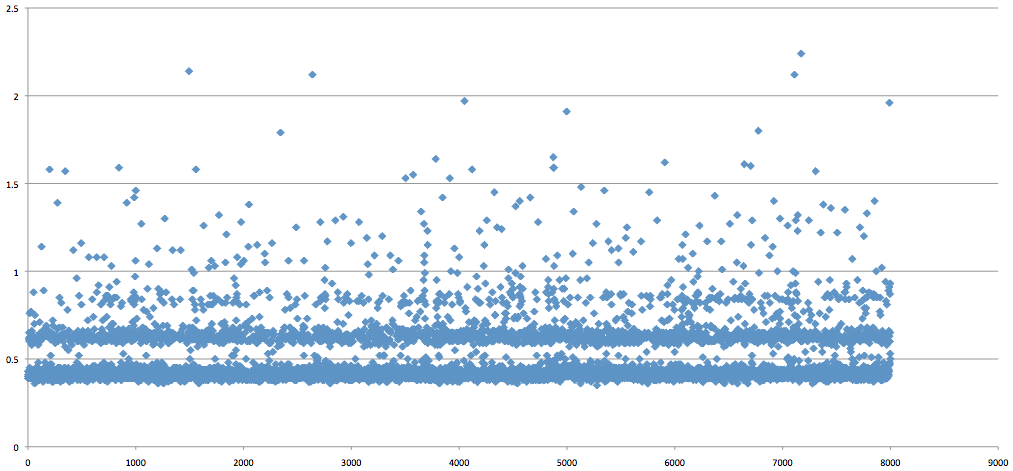
Not only is the initial gap (around 400ms) even more pronounced, but you can see a pattern of latency introduced at 200ms intervals after the initial 400ms delay. I have no explanation for this, but I wanted to publish these results and see if anyone else has a guess as to what might be causing these patterns.
UPDATE: To rule out any distortion caused by GNU time, I ran another test using Ruby's Time class to get a more accurate representation. In the most simple terms, we start the clock with Time.now, connect to the database (no caching), create a role, create the database and stop the clock. Output is logged and then imported into Excel for plotting. I think the results speak for themselves (measured in milliseconds):
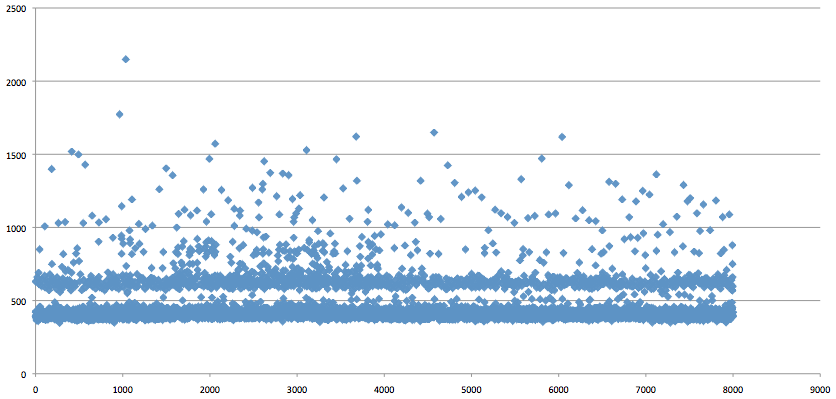
- Comments (1)
One Happy Ending
2011-08-25 12:47:34 by jdixon
Chances are you don't already know this about me, but I have a son who experienced a volvulus when he was three years old. This is a dangerous obstruction of the bowel caused by congenital intestinal malrotation (in other words, the bowels get "twisted" during fetal development). If the condition turns into a volvulus, the constricted portion of bowel will lose blood flow and die. In my son's case, he lost a significant portion of his large and small intestines. To be blunt, he was within minutes of death.
Nathan was unconscious in critical care for two weeks weeks, in the hospital for seven months, and has been back at home trying to resume a normal life for the past three years. It would be an understatement to describe this as a taxing experience for our entire family. The first couple years required my wife to quit her job and become his home nurse. Either of us would be up all hours of the night administering drugs, vitamins and refilling the pump that provides his nutritional formula.
The routine has eased over the last year, primarily in frequency and volume of administrations. But it still required staying up past midnight, every night, refilling his formula and managing the pump. One of the common conditions of short gut patients is an aversion to eating. Like anyone who's broken a joint, it can require months of rehabilitation. We arranged for an eating therapist to visit weekly, helping us work with Nathan to overcome his fears and get comfortable with the act of chewing and swallowing. It's an acutely frustrating process, especially for someone like me who has no problem with eating (wink).
Slowly and surely, he's increased his daily intake of "normal" food. What started as a few Cheerios (literally) eaten by hand a year ago, has increased to 1450 calories this past Saturday. His diet is still but a shadow compared to that of the average six year-old, but it's expanding each week.
And then, just this morning, the doctor informed my wife this morning that Nathan no longer has to use the formula pump at all. None of us expected this. I cried when I heard the news. I'm fighting back tears as I type these words. I can see daylight after all.
I hope this doesn't read as overly melodramatic. Truth be told, I didn't sit down to write this story for anyone else. But it feels good to write it down. To let the pain and joy and frustration and relief just pour out into the keyboard. It feels damn good.
You'll have to excuse me now. I'm going to take my son out for a hot dog. It's gonna be a great day.
- Comments (6)
Fixing Group Permissions after Migrating to OS X Lion
2011-07-31 22:17:51 by jdixon
I've discovered that restoring a user account from a Snow Leopard (10.6) Time Machine backup to a new system running Lion (10.7) fails to preserve membership in gid 20(staff). I don't know if this only affects users in this particular scenario or might affect other upgrades/fresh instsalls, but it certainly bit me in the ass. I first encountered problems when trying to brew update, only to discover that it wouldn't let me write anything to /usr/local even though the directory had group-write permissions. Lo and behold, I finally realized that my membership had been revoked.
$ id uid=501(jdixon) gid=501(jdixon) groups=501(jdixon),401(com.apple.access_screensharing),12(everyone),33(_appstore), 61(localaccounts),80(admin),98(_lpadmin),100(_lpoperator),204(_developer), 101(com.apple.access_ssh),402(com.apple.sharepoint.group.1)
The fix is simple enough. Use dscl to add yourself back to the staff group membership.
$ sudo dscl . append /Groups/staff GroupMembership `whoami`
- Comments (1)
Giant Robots Are Cool and Shit, But Seriously...
2011-07-15 16:54:34 by jdixon
I'm pleased to see so many people interested in the #monitoringsucks movement/campaign/whatever. My last post seemed to resonate with a lot of you out there. I'm excited to hear discussions surrounding APIs, command-line monitors, monitoring frameworks, etc. But I think a major thrust of my article was missed. It's not just that Nagios can be a pain in the ass, or that we need a modular monitoring system. What I'm trying to emphasize is that monolithic monitoring systems are bad and not suited for the task at hand.
Some very smart systems people (and developers) are trying to solve this problem in the open-source arena. Unfortunately, while they're attempting to diagnose and cure the problems in contemporary monitoring systems, they continue to architect big honking inflexible software projects. When I refer to "the Voltron of monitoring systems" I'm not talking about an enormous fucking automaton of monitoring, alerting and trending components. I mean that each component should exist independently of the others, with a stable data format and communications API. Any single component should be easily replaceable and deprecated. Authors should strive for competition because it makes the inclusive architecture that much stronger.
Realistically I see one of three things happening over the next 12-18 months:
- A community forms around a reasonable set of defined components and begins cranking out useful bits. Over time we have what resembles a useful ecosphere of monitoring tools and users.
- Motivated developers continue to solve the issues affecting monitoring software, but in their own walled garden projects. We benefit from a larger pool of projects to choose from, but they all continue to suffer from NIH syndrome.
- I'm disregarded as a nutcase. Nothing changes and we continue to use the same crappy ubiquitous software.
At this point I think the most likely outcome is a combination of numbers 1 and 2. It's hard for anyone to justify working on a disassociated component when the related components it needs to be useful might never be developed. On the other hand, if someone working on a monolithic project has the foresight to break up the bits into a true Service Oriented Architecture, then it would be feasible for external developers to fork individual units.
- Comments (6)
Achievement Unlocked: Heroku Operations
2011-07-11 11:59:56 by jdixon

I'm proud to announce that I'll be starting at Heroku in a couple of weeks. This is an exciting opportunity to work at a place that breathes DevOps and eats Infrastructure as Code. Whenever you hear someone describing "Platform as a Service", there's a good chance that Heroku will be the example they're talking about.
I first met Mark Imbriaco (@markimbriaco) when he was the Operations Manager at 37signals. Mark's a level-headed guy with a undeniable talent for Web Operations and an excellent track record for supporting his customers. It was no surprise to me when he took over as the Director of Cloud Operations at Heroku. Even after the acquisition by Salesforce.com last December, they've continued to innovate at a breakneck speed (proof here, here, here and here).
Heroku development and operations teams get to work on the sort of rapid scaling and engineering challenges that pique my interest. I'm doubly excited to be able to share the fact that I'll be joining up simultaneously with Curt Micol (@asenchi) as the newest Operations Engineers on Mark's team. It's an odd coincidence that we're both big fans of BSD. Hopefully nobody holds that against us. ;-).
Needless to say I'm thrilled about the whole thing and hope that it gives me more cool stuff to write about here. Stay tuned.
- Comments (2)
Monitoring Sucks. Do Something About It.
2011-07-07 23:45:30 by jdixon
For as long as I can remember, systems administrators have bitched about the state of monitoring. Now, depending on who you ask, you might get a half dozen (or more) answers as to what "monitoring" actually means. Monitoring is most commonly used as a casual catch-all term to describe one or more pieces of software that perform host and service monitoring and basic trending (graphs or charts). But in most cases, these complaints are targeted at software responsible for daily fault detection and notifications for IT shops and Web Operations. The usual whipping boy is Nagios, a popular open-source monitoring project that supports a universe of host and service checks, notifications, escalations and more.
Nagios has been the "lesser of all evils" for quite some time. Its cost (free), extensibility (high) and configuration flexibility have helped it achieve significant adoption levels across a variety of industries and range of business sizes, from small one-man web startups to Fortune 500 enterprises. It's been forked multiple times and is recognized by industry analysts as a force to be reckoned with. Regardless, those who use it, do so with a fair amount of hostility. Ask around and you're likely to find more users who stay with Nagios because it's "good enough" than those who actually like it. So why doesn't Nagios have more competition in the open-source marketplace? Largely because writing an entire monitoring system from scratch is an enormous undertaking. Ok, does that mean we should keep improving Nagios (or forking it... again)? Perhaps.
- Comments (10)
The Most Interesting Blog Post in the World
2011-06-08 23:11:40 by jdixon
The most interesting blog post in the world... is somewhere else. If I was one of those douchebags who tweets about an EXCITING NEW BLOG POST that is really just a vanity post to suck you in for artificial hits, then link you to the real story hosted elsewhere, you would find the link below.
But I'm not. So you won't.
- Comments (0)
Flying Cars and Food Capsules
2011-05-25 21:02:52 by jdixon
Today I was installing RHEL 6.0 on a remote Xen domU using virt-install with VNC. None of the Mac VNC clients I tried was able to render anything remotely usable. I tried various encoding schemes and color resolutions, to no avail. And where Chicken of the VNC rendered a screen seemingly inspired by LSD trips, RealVNC simply shit its pants and crashed.
So I downloaded an OpenBSD 4.9 iso and installed it in VMware Fusion. Installed tightvnc-viewer from packages. And in less than 10 minutes, I had a working X11-over-SSH tunnel to the remote Xen VNC console. From my Mac desktop. Through an OpenBSD VM. Across the fucking internet.
Welcome to the future. Sorta.
- Comments (1)
Trending with Purpose
2011-03-18 13:52:44 by jdixon
I threw together a presentation on short notice this week for an internal tele-conference about Trending with Purpose. The end result was much better than I might have expected (even given my penchant for procrastinating). Although much of the content is specific to applications currently in use at $DAYJOB, I think there's something to take out of it even if you're not using these tools.
The content is intended for developers who might not (or know how to) use application profiling data to complement their operations' monitoring and trending efforts. Special props to the Orbitz.com developers for open-sourcing their Graphite graphing tool, as well as John Allspaw and the Etsy Engineering team for their work on StatsD, and for generally serving as innovators in the Web Operations industry.
Special note: These slides were thrown together in rapid fashion. Anyone who experiences violent reactions to Gill Sans Italic should not download this slideshow. You have been warned.
The slides are available here.
- Comments (3)
Double-Spacers are Not Evil
2011-01-14 08:46:01 by jdixon
Recently, a torrent of criticism has been unleashed towards "double-spacers", bitching and moaning about our excessive keystrokes. Single-spacers en masse are mocking our outdated beliefs. They trot out their modern typographers, quoting type-space rules and style guides. If the level of vitriol is any measure, we've caused them a great deal of distress.
Yes, I admit it, I'm a lifelong two-spacer. The habit was learned as early as middle school, drilled home in high school, and reinforced in college. It's the sort of thing that becomes ingrained and part of your muscle memory. So trust me when I say it's no small task to unlearn this behavior. But I have absolutely no qualms about changing my spacing if it's the right thing to do. In fact, I've already started.
I'm not quite sure what teed up these people and unleashed their rage over such an innocuous thing. Are their lives so methodical that a few extra pixels cause their stabilities to unravel? I have little doubt that what they're preaching is the truth. That's not the crux of my issue. I'm concerned over their lack of reasonable discourse; what they fail to realize is that we double-spacers were trained in this manner over many years. We want to do the right thing. I'd be happy to save a few extra keystrokes. But I don't need to be chided to gain the proper motivation to do so.
In other words, don't be a dick. These are not the typographical equivalent of the Crusades. Publish your findings and make your point. Oh, and give us time to adapt. My delete key is working overtime.
- Comments (8)

 RSS 1.0
RSS 1.0